-
- Supercontest.
- Created and finished a small handful of improvements: https://github.com/brianmahlstedt/supercontest/issues/110.
- Changed that stupid logic where every new endpoint would have to be excepted in nav_active. Now it actively highlights profile if it sees edit_user_profile in the route. If there are others in the Profile bucket, I’ll add them as they come.
- Fixed the FMD, adding grouping by user email. The actual problem was solved by the docker system prune and docker volume rm (for the fmd only).
- Added an awesome admin navbar (custom).
- Redesigned the whole schedule interface. No jobs are automatically started anymore, and none are started at application started. Wrote a nice interface in the admin panel that allows you to kick off each job individually, and view the currently running jobs.
- Split it so that the lines job does not trigger the scores job. You must add both (and then they auto-trigger to actually start, of course).
- This makes it nice because you can individually tell the scores job to look in the db at already-existing lines and add future jobs for them. Otherwise, if the app crashed after the lines were ingested on wednesday, you’d have to go back in and add the score jobs again manually.
- Continually unimpressed by how fickle apscheduler is. Having fought more against it, I decided it was too unreliable to use in production. It was committing duplicate lines, not running at other times, and much more. It can’t even report its own status accurately. I’m going to leave it in place for the harmless, non-self-modifying jobs (email reminder). I’m not going to use it for the repeat-until-post westgate line fetch, or introspect-live-scoring.
- MemoryJobStore is fine if you don’t need to persist jobs across something like an application crash. If so, the SQLAlchemyJobStore would be easy to change to. You can use sqlite or postgres.
- The usual docker system prune -af, on both dev and prod envs. Wiped the volume for FMD, not the regular sbsc db. The usual git remote prune origin as well.
- You have to pass the csrf token in form submission (if the action is going somewhere that has csrf protection, like my site). It’s pretty easy: https://flask-wtf.readthedocs.io/en/stable/csrf.html#html-forms.
-
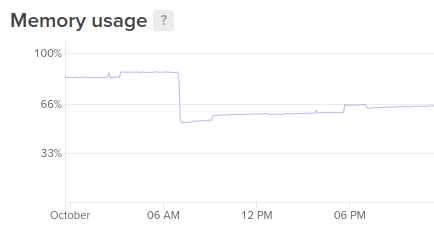
- Played with the new metrics agent on the droplet. It’s properly reporting data now.
- Created an email alert for mem > 90% for 5 min.

- I’ll grab this again over about a week, to see mem usage increase in O(days), as well as sunday action.
- CPU usage, disk i/o, process load – these are under control always, even on sundays. They only rail during a deployment..
- Ducati hit 6000 miles today.
- SF has a ton of food transportation startups.
- uWSGI needs to re-enable the GIL with –enabled-threads in order to work properly with APScheduler.
- Apscheduler doesn’t expose if a job is running. Absolutely ridiculous.
- Chiro
- Jinja blocks {% block %} cannot be conditional, you must put the {% if %} within them, not around them.
- Started the brine for pastrami beef ribs. Basically just make a usual rub, but with about a tablespoon of pink curing salt. Bring half gallon of water to boil with the rub mixed in, the add the other half gallon of water to cool and then submerge the short ribs for a week.
- Supercontest.
- Added ADMIN_EMAILS to supercontest.util.email. Made each schedule notify me of start/stop as appropriate. Confirmed the following:
- Email reminder runs once, and emails me the summary as admin.
- Line fetcher prints every minute.
- Live scoring verifications, in order:
- Comment out all of commit_scores until the live definition, then modify as necessary.
- Add to the bottom of get_app() before the scheduler.start() call:
- import datetime
- from supercontest.schedule import add_live_scoring_jobs
- datetimes = [datetime.datetime.utcnow() + datetime.timedelta(minutes=1)]
- add_live_scoring_jobs(datetimes)
- Visit the /scheduler endpoint during all of these tests.
- Tests:
- Scores are fetched every minute if a line’s datetime is reached.
- Shim the datetime input to add_live_scoring_jobs() with one datetime and live = True.
- Score fetching only runs one job when multiple games are active.
- Shim the datetime input to add_live_scoring_jobs() with 2 datetimes at the same time. Keep the live status.
- Score fetching is stopped when all statuses are F/FO.
- Set live = False. Make sure it emails you.
- Future schedule jobs remain after removal of the current.
- Add a third datetime before the other two. Leave live = False. When it is removed, make sure the next two are still scheduled in the future.
- Then undo the first two actions.
- New lines end the fetch job, and an email is sent.
- I’ll have to verify that the score fetching works fully, with real data, tomorrow.
- Fixed the cyclic imports by lazy-loading the wrapped functions inside the job targets.
- Adding a new navbar for admin (dashboard and scheduler). These do not participate in the nav_active regime.
- Updated banner, usual wednesday deploy.
- Deployment takes about 4 minutes.
- Was getting a weird KeyError: 5 in the limbo period between 5pm when the db week turnover and the new line commit happens. Could not reproduce in the dev env. I’ll check next week again. Could have been some compound issue with the broken line fetcher (hopefully…bc that’s fixed).
- Added protection that if the lines are already in the db for the current week, remove the job and stop (don’t commit scores, don’t run another fetch again, don’t email, etc).
- Split up the templates into a navs/ folder. SO much better now.
- Consolidated all the menus into one smart huge navbar. The template hierarchy is a lot cleaner too. All of the nav dropdowns are sequential, and then the final view extends them + fills out the main_content block.
- Every view has league now. All of the conditional if statements to build url_for() calls are much simply now. It’s just one branch at max, checking if week is needed.
- Played with the responsive capabilities of navbars: collapse at certain breakpoints, splitting into different submenus, etc.
- Remember that to delete a row with fk constraints, you must delete those rows that reference them (for example, you can’t delete line rows until the score rows that reference them are deleted as well).
- The jinja block you’re filling doesn’t have to be in the direct parent you’re extending. It can be way up the lineage.
- The href=”#” on an <a> tag tells the browser to treat it like a real link. Without that, it won’t show the click cursor (the hand) – instead it will show a regular pointer or typing cursor.
- FDT needs a body tag, so add it if you want the toolbar for even basic endpoints that return pure html or raw strings.
-
- I’m 0-8 in fantasy so far!
- Appointments.
- Got the MRI. Much better waiting room, they got me in right away. Photos took 45 minutes. I was lying in full superman position without moving, which became horrible with pins and needles toward the end.
- Orthopedic = musculoskeletal. I had incorrectly thought it was only bones.
- Made appointment for the followup in Van Nuys. Would have done Culver, but I needed to get my license back from NoHo anyway. You can’t replace a DL through the AAA DMV services, and the soonest appointments for the Hawthorne and Torrance DMVs were December.
- Supercontest.
- I had to set MNF’s status to F for some reason. It was stuck on 4, even though the NFL xml was returning F. All of my score updating improvements today will change that bit.
- Last week was the worst league-wide performance since the beginning: 31.9%. Nobody got 4 or 5, 3 was the highest. There were four 0s.
- Cleaned the main __init__ quite a bit (the internals of get_app()). All extension capability is well organized and properly imported now.
- Split the determine_coverer/points logic into the wrapper (which expects rows) and the wrapped (takes raw values). This was useful because certain pieces of the app call these functions in those two separate ways.
- Generalized get_matchups and get_picks to be more modular, rather than using specific wrappers for each distinct queries. It’s going to be easy to manage, the args basically mirror the cols 1:1, then the filters just add whatever was requested.
- Change it so points and coverer are now BACK in the db. They are written to by the apscheduler job, depending upon when games are live. They are read by everything (mostly in results), which simplifies a lot of duplicate logic.
- Machine went from ~300 to ~600M in mem usage over 12 hours after restarting the app but not doing anything (like a deployment). Not good. There’s clearly a leak somewhere.
- Used a psql CASE WHEN THEN ELSE END statement for the migration, to populate old coverers and points. Just like an IF statement in a higher level language.
- Added the proper apscheduler jobs for live game scoring, as well as line fetching.
- Created the tickets for the next two (should be final) efforts:
- Made the jobs not run in the off season.
- Updated docs.
- No thanks: https://gfycat.com/miniaturespanishkronosaurus-adventure-v-travel-nature-matterhorn.
- What few colleges teach you about the fastest escalator to corporate success is the art of asskissing. Relationships (politics) mean more than individual contribution (skill) in most offices.
- 7’9″ is the tallest anyone has ever been without any of the usual disorders that cause extreme height (gigantism, etc). https://en.wikipedia.org/wiki/List_of_tallest_people. He was just a statistical anomaly, the furthest end of the regular human height range.
- Started the final 8 mile training run and my left foot nerve pain was too much to continue after ~3.5 miles.
- Running was more painful in the knees/hips/back when landing on the heels, but I couldn’t mid/toe strike because of the injury. Barefoot running really is so much better, but I’ll have to be more gradual with training to strengthen my feet/ankles/calves.
- I will definitely run the race in the full purple shoes, with tape over the right outer hole that had formed (will donate after race).
- Re-downloaded strava to start logging the training again.
- flask-apscheduler attaches the actual apscheduler base scheduler at scheduler._scheduler, which you can use for some stuff that the flask extension stupidly hides (like print_jobs()).
-
- Abdulrashid Sadulaev is a 23yr old Russian wrestler. He is the current world champ. He’s from Dagestan, just like Khabib.
- Awesome pin of the defending champ snyder with some offshoot peterson roll all the way to fall? https://www.youtube.com/watch?v=Ryy19IY9fQo.
- Supercontest. Worked on async score fetching and result calculation today.
- Design decision: Score.coverer and Pick.points will update in realtime, as the scores change, rather than waiting until the game completes. This allows you to present mid-game date as “what if the games ended right now?” For views that don’t want to bank games until they’re done, like the leaderboard, you can filter with an additional check for FINISHED_STATUSES.
- If the app is down for a game, you have to manually enter the information into the db. This is fine. Based on the xml scoresheet that I pull nfl scores from, the only option is live. In order to get past data, I’d have to hit another API.
- sqlalchemy difference between default and server_default: default is just what python will insert for the value if you don’t provide one, server_default is a statement that you can use to generate the value on the db side.
- Chubbyemu videos are so interesting and informative.
- The patriots, the chiefs, and the NINERS are the only teams still undefeated.
- Ordered pink curing salt to make pastrami beef ribs with the next 2 racks. Curing salt is basically just table salt (sodium chloride) mixed with sodium nitrite. The pink doesn’t matter, it’s just dyed to make sure people don’t use it as table salt (although pink Himalayan salt can be used as table salt, and it’s obviously pink too). Regular sea salt can be used to cure/brine meat as well, obviously, it just can’t go as long because the nitrites are what protect the meat from bacteria growth during the curing process.
-
- Supercontest.
- Added tons of stats for the history of the league. https://github.com/brianmahlstedt/supercontest/issues/23. Super interesting.
- The submit button stays up after someone clicks it. That was the problem. Fixed it and removed a few more duplicates.
- cache.memoize on get_picks was causing problems if you made multiple pick submissions within the span of 10 seconds, because the client would be told about picks that might have been old, desyncing from the actual picks in the backend db. Fixed (by removing the cache for that query). Pick information should be live on request. Scores are different, because the user doesn’t write to the scores table from the frontend.
- Completely cleaned and reorganized my room. Cleared a bunch of space. Including closet, lights, everything.
- DigitalOcean.
- Did some research, you can upgrade any of disk/cpu/ram. It adds a decent amount to the monthly cost. Just going from 1GB memory to 2 makes it $10/mo instead of $5.
- Allowed password login on the droplet for my user, so that if anything goes wrong remotely, I don’t need my laptop and ssh key. I can just ssh from any machine.
- sudo vim /etc/ssh/sshd_config
- PasswordAuthentication = yes
- sudo service ssh reload
- sudo passwd bmahlstedt
- Confimed that I have access. You can ssh in like usual or you can go to the DO website in the browser and access a console from there. Password is one of my old SpaceX ones.
- Upgraded from the legacy metrics agent on my droplet to the current one.
- tmux shortcut reminders.
- To detach from your current session, just type your hotkey then d
- To kill your current session, just type your hotkey then : then kill-session
- If another client has another session in a different window size, just kick them off when you attach with tmux attach -d
-
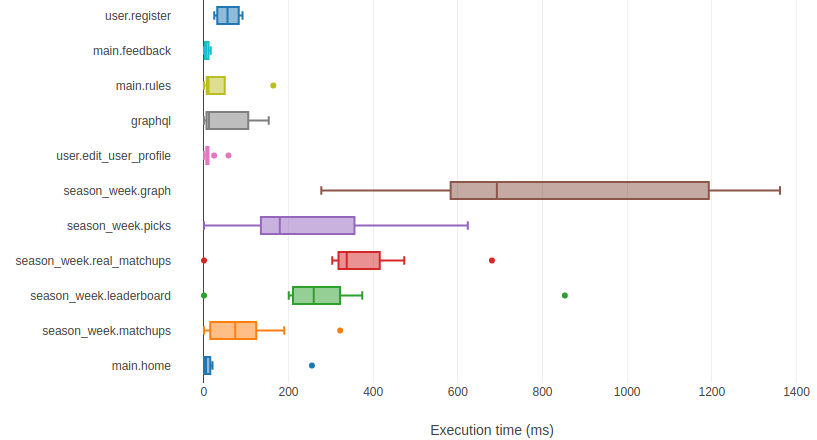
- I care much less about the API utilization metrics that FMD provides. The most interesting is the API performance. Graph below. I wish they had multi-version api perf like they do for utilization. The results are mostly expected, but still an awesome feature. https://southbaysupercontest.com/dashboard/api_performance.

- In checking back, you can see multi-version api perf for specific endpoints! Just not an overview of all routes for the application.
- South Park is back!
- FMD
- Verified that it CANNOT do patchfix version resolution. Only major and minor.
- A major version (3) was released yesterday, which appears to have broken the overview page. 3.0.3 was released a couple hours ago, looks like they’ve had a few bugfixes. Upgraded, and confirmed the overview is still broken.
- Maybe this line of questioning will help the lesser perspectives understand the ignorant racism in the NBA owner concession:
- Is it ok to compare someone to Saddam Hussein, when they have nothing in common with him except that they’re Arab?
- Is it ok to compare someone to Hitler, when they have nothing in common with him except that they’re German?
- Is it ok to compare someone to slaveowners, when they have nothing in common with them except that they’re white?
- It it ok to compare someone to <anyone bad or good>, when they have nothing in common to do with it except that they share the same race?
- No. None of these comparisons are ok. They’re offensive. Doesn’t matter the historical subject/object, victim/aggressor, small/large, green/orange, old/young.
- All daemon threads will be killed when the last non-daemon thread dies. The non-daemons are the main ones. The daemon threads are subservient – they will not hold the main app.
- Supercontest.
- Got a few “AttributeError: ‘AnonymousUserMixin’ object has no attribute ‘id’” errors in the production app, with an IP from singapore. This just means they tried to access a route and weren’t logged in. The flask_user.current_user object is AnonymousUserMixin when the user is not logged in, so they can’t do anything. The error was caught pre-route in the url_value_preprocessor.
- Right now, I have 94 compiled requirements (including testreqs) and 26 input requirements (not including testreqs).
- Remember that while 99% of requests make it to the app and you can check the standard uwsgi/flask logs (make logs-prod), there’s a small chance that nginx catches something. just run `docker logs -f nginx-proxy` to check.
- Added text for harner’s banner.
- Tons more work on the redesign of blueprints, routes, url_prefix, url_defaults, url_value_preprocessor.
- Used request.url_rule.endpoint and request.url_rule.argument to infer all of the values (in g) that the current view would have access to. Then I conditioned the url_for() navlink builds in the templates based on those.
- It’s all in a great place now. This was frustrating for a few days, but will be much easier to manage/change in the future without breaking things.
- Closed https://github.com/brianmahlstedt/supercontest/issues/102.
- Added apscheduler (advanced python scheduler) for the weekly email pick reminder.
- Not sure how, but two people submitted 10 picks into the db. Both were pairs of the same 5. I deleted them manually, but I’d like to know how this happened.
- Split up the utilities module into a separate util package, containing distinct modules for the specific type of functionality they provided. It was getting too big.
- Originally wrote the email reminder with apscheduler, but there’s a specific flask-apscheduler that made it a little easier. Don’t need to manage the debug app duplication, atexit, or any of that peripheral wrapping.
- Tested with my email only and a modified cron. Worked! The apscheduled job shows up in the regular flask logs too.
- Closed the weekly reminder ticket: https://github.com/brianmahlstedt/supercontest/issues/97.
- In debug mode, flask loads two instances of the application. If your app does something like schedule an external cron job, it will happen twice.
- Added Google Keep back to phone and to browser bookmark. I was missing the ability to immediately open something and jot a note down, especially while I was out and about, away from my laptop/blog.
- The `date` command in bash gives the local datetime with tzinfo.
-
- The amazon rewards card gives you 3% back at amazon. There’s also a “reload” feature on amazon, where you put money in your account (for use at amazon) and it gives you 2%, plus $10 bonus sometimes. I tried reloading WITH my rewards card today. It won’t let you.
- Electric toothbrush finally died, bought a new one. $50. Arrives tomorrow.
- Went to ortho in Van Nuys, got an MRI referral. Total round trip: 2.5 hours. 1.5hr driving, 1hr in waiting hour, 5 min visit with doctor.
- So far, the entire chain has been:
- spacex doctor -> spacex pt -> general doctor -> bloodwork -> general doctor -> xray -> general doctor -> ortho doctor
- 8 appointments, 8 visits, 0 conclusions. The referral system in medicine is terrible.
- There will be more. MRI -> ortho doctor -> whatever is next (hopefully not just PT).
- Idea: there should be a global medical database. You have to fill out the same new patient forms at every clinic you go to, and 99% of it is the same.
- Every office would have auth keys to a specific subset of the db: general information, surgical history, family history, ortho, respiratory, psychological, whatever. There would be a ton of different tables and only your office’s specialty would be accessible by your office.
- This is just chrome holding all your passwords. They’re collocated in a higher layer, the browser, and then every site uses only the ones it needs (and can only access the ones it needs).
- This would make the patient experience easier, would make referrals easier, would make everything easier.
- You could also do some machine learning once all the data was collocated. I guarantee there are correlations we don’t see yet because all the variables are never observed together.
- Jinja can understand **kwargs, but the syntax is a little bit different than python: https://medium.com/python-pandemonium/using-kwargs-in-flask-jinja-465692b37a99.
- Supercontest.
- Week 4 did not become available at 10am PT, which would have been the case if I had messed up the timing (because that’s 5pm UTC).
- Restructured almost all of core/results, and its corresponding usage in views, to be sequential. Query for something, pass it to something else, sort it, calculate from it, etc. It’s a much clearer, layered approach now. The analytic functions are modular, no queries are being repeated. Establishment of the necessary information happens FIRST, in the route, in the highest level. It’s much easier to see duplicates now.
- This modularity made my query footprint a lot smaller. The all-picks view would query for all users but only one week, whereas the lb/graph would query for all users for all week. They used the same machinery underneath, but the latter called it in a loop. Now it queries all at once and reformats the data as desired after. I remember thinking about this inefficiency when I first wrote it, but didn’t have time to optimize. I do now.
- Commented out all the tests so that I can run test-python to completion as it should. All no tests run, it’s still gives more information to add this properly to my dev workflow (it compiles requirements and such).
- Tested and work. App is a lot snippier, and FDT shows a lot fewer queries (like 10 max, for the worst route that has to query everything).
- Updated to harner’s gif. Played around with the background css styling. There are two important ones: background-repeat and background-size. “space” will keep the original size but fill in gaps with whitespace, “round” will distort the image within a slight margin to fill the gaps (both for repeat). For size, you can basically stretch it or keep it the same, fit in parent, etc. Looks good now. Fits one across on mobile, and repeats on larger viewports.
- Made the app gracefully handle the time period between 5pm PT (week_start) and when westgate posts the lines, if there’s a delay. It conditionally shows messages, and even omits the table.
- The heaviest (time-wise) route in the main navs is /graph. The heaviest league is the free one, because it’s the least filtered. And the heaviest season is any full one. Therefore, the current view that takes the longest to load is https://southbaysupercontest.com/season2018/league0/graph.
- Removed wednesday from RESULTS_DAYS and just added a single commit_scores call within commit_lines, so it initializes properly.
- Added queries.is_user_in_league and g.user_in_league.
- Fixed a few things to make the new “return empty but valid results for new lines and new picks” work.
- Confirmed that newly committed lines from westgate enter the db with timezone info, and timezone = utc (the rest were manually added to the migration – I wanted to make sure it was consistent.
- Did the usual wed deployment.
- If you follow a ctag in vim, don’t edit it there. It won’t save by default. This is just for looking.