-
- Remember inner join ignores nulls, so if you’re joining on a nullable column (like
scores.coverer_id to teams.id), you need to do a LEFT join (if scores is on the left of the join, RIGHT if right).
- I use 3 oils for cooking: peanut oil, olive oil, and bacon fat. Lean toward bacon whenever possible. Better flavor, 100% unrefined, etc. The most important other consideration is smoke point: bacon has the lowest, then olive, then peanut has the highest. So for panfrying something on high, must use peanut. For cooking eggs in a skillet on medium, bacon fat is fine. Olive for medium-high pan, or baking.
- SBSC. Continued on the generated cols effort. Results views for coverer and pick points.
- Played with
sqlalchemy-utils‘ observers a bit more.
- Confirmed that they ONLY run when the observed cols change, not on data access.
- Confirmed that it ONLY runs in the ORM layer. If you change the observed cols in psql directly, the observer col does not update. You’d have to go the view +
GENERATED AS col approach for that, but I’m fine living in python for modifications. Shouldn’t be mucking in the db anyway.
- The observer acts as a materialized view. The col is stored. You never have to write it (it also acts as a default!). It’s avail for read.
- You have to
session.commit() to trigger, obviously, because the observer runs in the before_flush phase.
- The only imperfection (but still liveable), with a score example: The
Score.line relationship needs to exist for the Score.coverer col to be autopopulated, since it pulls from the line relationship for cols to calculate from. At at Score creation time, this isn’t the case; the line relation hasn’t been created yet, the Score is only instantiated with line_id. But that’s ok. We have the ID, we can pass the Line object. This ticket is in the business of speeding up reads not writes.
- Made the observer columns manifest as IDs, and FK to the appropriate remote table. And then a normal sqlalchemy
relationship to pull the object back for convenience use in the ORM. Very clean.
-
- All obvious, but a good overview of the softer culture/process hacks at companies: https://steinkamp.us/post/2022/11/10/what-i-learned-at-stripe.html
- Some private work.
- Massage Envy attempted to charge for a monthly billing cycle after the account was closed. I emailed Rosly, and disputed the charge via citi (well, it will file formally once the charge changes from pending to posted).
- She replied and confirmed the cancellation.
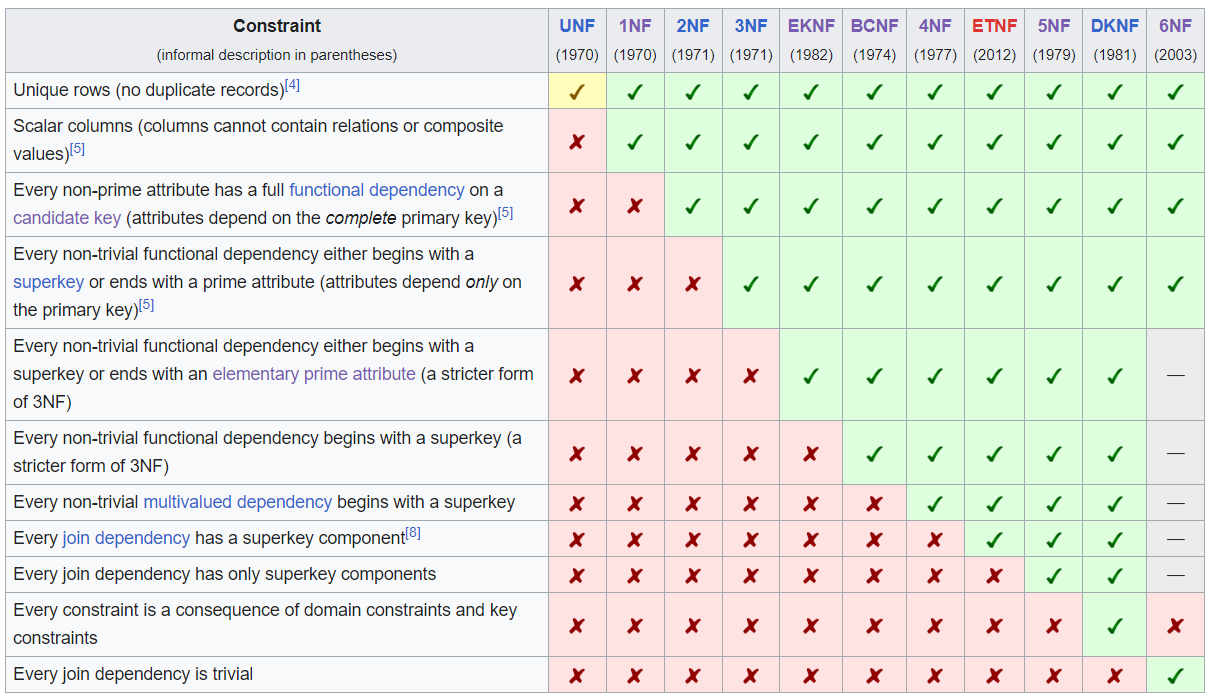
- DB Normalizations.
- Remember they go in strictness order. 2NF is more strict than 1NF. 3NF adds more constraints on top of 2NF.
- I only go over some of the more important distinctions below. There are many more conditions.
- Note also: these only apply to the cols of the table itself (PK, FK, other cols), not sqlalchemy relationships. Those are for the ORM.
- 1NF. Single-valued attributes for each table. No lists. Split those into distinct rows.
- 2NF. “Reduce to atomic tables” – no partial dependencies between cols. Those should be moved to separate tables. Example: season and week, separate tables, if there was just one weeks table with the season info then there would be partial dependencies between the season, season_start, season_end cols in the weeks table.
- 3NF. Same as 2NF but for transitive dependencies between cols. Restated: the relation between the atomic tables is only an FK to the PK, not multiple items or a transitive item.
- ^ That’s where most RDBs can stop normalization and be free from update/insert/delete anomalies. They may still have some redundancy.
- 4NF. Multivalue dependencies. If you a table that has 3 cols A/B/C, split into 2 tables with 2 cols each, A/B and A/C.
- 5NF. Joins are along superkeys (unique value-combos in a row). PK satisfies this.
- 6NF. Every table has at most 1 join dependency. Most common in practice where every table just has a PK and one other col with a value.
- SBSC is 5NF.
- Helpful overview: (ref https://en.wikipedia.org/wiki/Database_normalization)
- SBSC. Started on the results views, for
coverer and points.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/174
- Remember that queries operate on the class of the models, and return instances of those models. Relationships provide their convenience in the latter – for accessing data on objects rather than querying for those objects. You can do a few things with class relationships in the query layer, but mostly for EXISTS (has/any) and comparators (equality). You can’t fetch a value along a relationship and use it in a query, for example, because the relationship requires an object, not a class. So you’d have to subquery to get the object, or something along those lines.
- Sqlalchemy has the
case func for if statements in sql. Maps to when.
- Did a ton of research on options for views in sqla. The native sqla recipe (https://github.com/sqlalchemy/sqlalchemy/wiki/Views),
sqlalchemy-views, and sqlalchemy-utils. I went with the latter. It has a ton of useful tools.
- You can achieve the
Computed behavior of the coverer/points cols by using aggregated or observers. Both support nested relationships to denormalize and bring in data from other tables (like coverer needs Score and Line).
- Aggregates are much better when the one-to-many relationship have thousands of objects on the many side. It does a query for all of them and runs a func on it to product a scalar (an aggregate of your definition).
- Observers are much better for one-to-one or one-to-few, since it just iterates over the related objects, in the transaction. Using observers for this case, since
score.coverer only needs to bring in the one line object (line, favorite, underdog), and pick.points only needs to bring in the one score object (the new coverer col).
- All summarized: need to do a bit of denormalization to calculate the results cols.
-
- Humidifier cleaning: https://cdn.accentuate.io/7062932586584/1649372746090/D1_02.00_M1_LUH-D302-WUS_2022-01-14_US_PRINT_en.pdf?v=0
- Everything about poetry env management is for different python versions within a project: https://python-poetry.org/docs/managing-environments/. I wish you could create named envs per dependency set. I want a dev env. I want a test env. I want a doc env. I currently do
poetry install --with [dev|test|doc] for those, which takes my single py3.11 project env and makes sure it has the proper deps, but that takes a few seconds – why can’t I just prebake envs that match those depsets and then (eg) poetry env use testenv?? I could create a my own venvs for these and pass the python executable path of them to poetry, but then there’s a required step outside of poetry for dependency management. Defeating the whole purpose of using a pkgmgr framework.
- You can run
flask db upgrade if you’re 2 versions behind, and it will apply them both in order.
- Was going to switch verizon autopay to CSR (from boa debit), but remember that you get a big discount with debit. So left it. But the debit expires in 3 months. BoA should send me a new one, and I’ll change it. Added a calendar note.
- Awesome video showing how much more frequently spacex has been launching over the years: https://twitter.com/stem_feed/status/1630971547434221578
- You can’t just wrap a div around multiple td elements. Use selectors on the rows/cells as necessary.
- SBSC. Finished the statuses/teams tables.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/175
- Also moved
ansible and flask-debugtoolbar to group.dev.dependencies. Added a devenv target to makefile and made it a requirement of other targets that do poetry run ansible <> (just like I do with testenv targets and docenv targets). Removed ipython from all depsets.
- Bcrypt-hashed all the backfilled-users’ passwords (generic) with passlib via
flask_user.
- SQLA can only join to a table once. If you’re joining to a table twice because you have 2 FKs that you want to filter on (like
Line.favored_team and Line.underdog_team requires 2 joins to the Team table), set up aliases for the table and join over the aliases. Note that the table aliases should be used in the filter as well.
- With postponed evaluation of annotations (https://peps.python.org/pep-0563/), you don’t have to pass models in quotations to
Mapped[<model>] attributes. But static analysis tools still flag it, since python doesn’t hoist. Going to leave them quoted.
- Deployed new tables and app to prod.
-
- Confirmed that I’m no longer getting the cloudwatch costs. The actions worked, either the removal of the dashboard or the only-send-disk-stats-for-/ rather than all 30 mounts.
- ELB and EC2 cost cleanup will happen with the next few tickets.
- Ordered a bunch of seeds for strawberries, flowers, and microgreens. Through rise gardens (with all my member discounts), it’s about $2/plant. Pretty good deal for produce (single-costs aside for hardware). Can go even lower if you buy the seeds separately and use the seedless pods.
- Picked up the Ducati from MotorGrrl. Almost exactly 6 months in storage. Got a formal NYC inspection. Rode home smoothly. Total round trip was ~90min, not bad at all. Will do my maintenance later.
- New garage policy – no battery tenders. I’ll plug it in later. Everything is by the book under new management right now, but they said that later it will ease up. Overall, Icon has been an extremely poor vendor for everything I need in a parking facility.
- Updated to vscode 1.76: https://code.visualstudio.com/updates/v1_76
- Note that WSL runs independently (as do all processes within). Vscode is obviously my shell into the machine and all my workspaces run there, but the actual VM is managed by docker desktop on the host.
- SBSC. Continued on the data layer.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/175
- Make sure to join the appropriate tables in a query if you’re conditioning on a relationship. If no
where clause requires a child, then you can just select the parent table without any joins. Sqla will lazy load the relationships upon access. Best to be safe/explicit though.
- Made the main matchups functionality just return
list[Score] instead of list[Score, Line, Week, Season]. The appropriate children can be accessed via the transitive relationships. Same for picks. It returns list[Pick] only, instead of list[Pick, User, Score, Line, Week, Season].
- The default cascade is
False, or "save-update, merge". This applies when, for example, changing a Pick object; the Status child and the Line child are not deleted, since cascade="delete" is not specified.
- Resolved this issue:
Parent instance <x> is not bound to a Session; (lazy load/deferred load/refresh/etc.) operation cannot proceedflask_caching. Remember flask_sqlalchemy creates a scoped_session per request, so if your second request hits the cache, python will return the same result objects, but they’re dangling. So any access of child objects (via relationships) will fail with the above error.
- You could change the loading paradigm (ie make another trip to the db to make the object in-session and not dangling), but then you’re making the cache worthless anyway.
- Deleted the
matchups and allpicks views in postgres. It’s just so much easier to query from python where the ORM allows easy joins and relationships.
- Finished modeling the
teams table and all FKs + relationships.
- Successfully ran the migration.
- Just need to update all callers now.
- If you have multiple FKs linking 2 tables, you need to tell sqla which one to use when joining (in the relationship definition): https://docs.sqlalchemy.org/en/20/orm/join_conditions.html#handling-multiple-join-paths
-
- Full hedgineer podcast episode released today: https://www.youtube.com/watch?v=3VIGPUsKbAE
- First snow of the season last night!
- Lots of private work.
- MotorGrrl confirmed I can pick the ducati up before the end of the day tomorrow to avoid the March invoice.
- QBR = quarterly business review.
- SBSC. Continued on the new statuses/teams tables, and many corresponding changes that I folded into this ticket.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/175
- Wrote a new
supercontest.models.schemas module. I want the frontend views to match the DB tables as much as possible, keeping app logic thin (and this will only get MORE true with the generated-cols change for results), so the passage of sqlalchemy rows to the frontend becomes more and more direct.
- Since sqla rows are not json-serializable, we have a few options: parse to json-serializable objects (what I was doing before), use python’s builtin
dataclasses module, or an industry-standard third-party. I’ve chosen the latter, marshmallow, since it (as a serialization lib) has plugins to both flask and sqlalchemy.
- Read through the
flask-marshmallow and marshmallow-sqlalchemy docs.
- Included the FKs and relationships in the schemas, and made the relationships nested with the child objects, rather than just PK (marshmallow’s default).
- Note that I had to make the schemas uni-directional for this (all model relationships are bidirectional). This is obviously because it would result in an infinite-length string when serializing. The python ORM doesn’t have to worry about that, all bidirectional relations point to the same underlying/respective object.
- Did a TON of js cleanup.
- All view-specific modules are now pure (functions only), bundled in full by assets but called only in the views they’re needed.
- Merged some of the common behavior (like flashes) into
common.js.
- All the html is correspondingly better; variables are serialized as necessary before being passed by flask, then rendered by jinja into js vars. ONLY the vars necessary are passed, not the overkill of the previous
flask_vars_to_js.html implementation.
- There was a ton of ridiculous
id="<var1>-<var2>-<var3>" behavior in the templates so that js has access to things like userId that jinja populates in the loops. All gone. The js does proper lookups now.
- All of this will clean even further with the React splitout.
- Made it so that
- appears on the regular leaderboard for weeks that were unpicked (rather than 0). A red 0 appears if they submitted 5 picks and hit 0. A regular 0 appears if they did not submitted 1-4 picks and hit 0.
-
- When you update/insert an object with sqlalchemy, write the FK (eg
Score.status_id) not the ORM relationship (eg Score.status). The relationship will autoupdate to the proper object in the other table, based on the FK.
- Bit of private work.
- A big slowdown: running db queries and/or commits in FOR loops. Run them once outside the for loop for a single trip to the data, then store in hashed structures for the python in-memory layer (dictionaries etc). This affected the tables ticket because it helps design queries/commits to return data for iteration/lookup (rather than single functions mapping one datapoint to one datapoint.
- Productivity. Deleted “scratch tasks” note from gkeep. I just scratch on the tickets with intermediary tasks. No need to have a full note all the time, empty almost always. Just create as necessary for non-ticket tasks, or use the appropriate medium for the other tasks. Now my to-do scope is purely gtasks and gcal.
- Don’t use windex on acrylic. The chemical compounds will break it down over time. Bought an acrylic-specific cleaner (and repellent) for the outside of the aquarium.
- Emailed MotorGrrl to see if I can pick up my Ducati on Mar 1 first incurring the next billing cycle.
-
- Lots of cleanup in SBSC. Will post details soon.
- Getting a lot of spam comments on the blog lately (just going to the review queue, not public).
- All prep: software planning, mealprep bacon, oat milk, hibiscus tea, seed powders, new white bulbs in salt lamps, power cable organization, garden care, deepcleaned coffee machine, aquarium maintenance, set up second ember, roomba, cleaned.
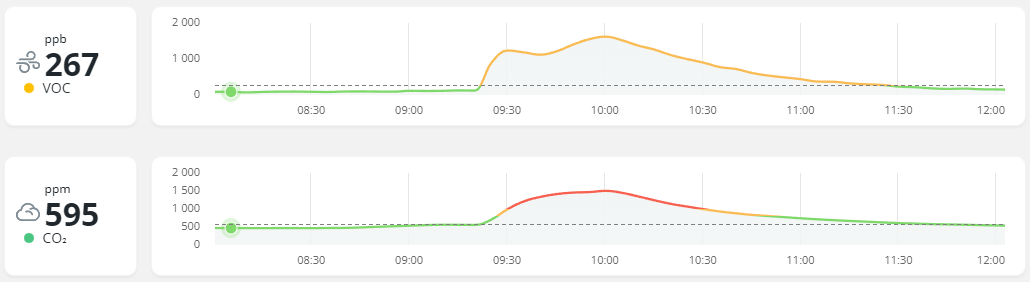
- Interesting. Cooking bacon (oven) spiked my CO2 and VOC levels significantly. Opening the window cleared it within an hour. Temp/humidity/radon/pressure not affected by the cooking.