-
- Haven’t heard from Gemini in a while (still checking https://www.gemini.com/earn, posts are minimal). Next genesis bankruptcy hearing is next wednesday.
- Remember that in addition to resident parking in my building, I can request discounted guess passes for single day. Check gmail.
- SBSC. Continued on the generated cols ticket (and the much-inflated scope).
- Almost done with the rewrite of the stats module. So much cleaner now with variable hierarchies, adjacency matrices, and dynamic generation of all univariate and multivariate plots.
- Created a new
supercontest.util.math and supercontest.util.plotting module. Also added supercontest.util.results back, for everything supplementing the core results/stats modules.
- Removed some more pylint disables, mostly
too-many-* by refactoring heavier functions into multiple.
- This included splitting the toplevel
create_app factory into multiple functions, logically separated by environment initialization!
-
- Hedgineer ep 2, Neel Somani (Citadel). Web3 dev, commods, eclipse, zk proofs, batteries, terra luna: https://www.youtube.com/watch?v=SIVQ8QxBIu0
- The official cutoff for UHNWI is $30M. HNWI is only $1M.
- Upgraded apt pkgs on the EC2 instance. Docker system pruned to reclaim disk too, was at 90%. Now 10GB of 30 used for /.
- Ordered fresh. And 10lb peanuts for bars.
- Lots of private work.
- Finished a massive redesign of the
stats module. Haven’t finished implementation quite yet, but the design details (in full) are here: https://gitlab.com/bmahlstedt/supercontest/-/issues/174#note_1305892617
- Made the html/js portions of the plots on the stats view dynamic. No more hardcoding ~200 plots.
- Created a gcontact (in my personal) for brian@privateerliquidity.com. Merged it. Opened the calendar-external-sharing settings in gworkspace admin console, and shared brian@privateer with my personal so I have a consolidated schedule for now (will segregate later).
- Did a ~medium dive into plotly, on both the python and js sides.
-
- Lots of private work.
- The errant massage envy transaction posted today, but so did its cancellation. Did not need to submit a dispute.
- Created google workspace.
- Added the MX records to route53. All around pretty easy process.
- SBSC. Continued the generated cols ticket.
- Fixed the issue where the graph view (“progression”) would compress weeks with 0 picks (rather than flatlining and keeping all graphs season-long). This was broken in prod too (not just my branch).
convert_num_to_int_if_whole and get_percentage are now passed from the app as jinja globals, rather than defining a duplicate macro in html for the same logic.- Used to delete old picks and recreate all 5 if the user changed 1 pick. This isn’t necessarily harmful, but causes a lot more writing than necessary, and ratchets the PK ID of the picks table up very quickly. Would be nice if I was storing history, but I’m not (outside of logs). Now it just updates pick rows as necessary. Max 5 per user per week.
- Mode the score write more efficient as well.
- Rewrote the entire
stats module.
-
- Lots of private work.
- SBSC. Continued on the effort for computed cols.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/174
- Effectively rewrote the whole
results module today.
alltimelb and stats views did not commit scores before building the dataviews. Now they do. Just like LB/allpicks/matchups/etc. It only does this during the regseason, and on SCORE_DAYS, of course.lb / graph / alltimelb views don’t query for scores anymore. They just need picks.- The
alltimelb used to just run the lb for every season. Now it’s distinct; it just iterates over all picks (mapped by season -> week -> user -> data), just like all other views.
-
- SBSC. Continued on the generated-results effort.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/174
- Rearranged the cols on the matchups view a bit: datetime on left, location on the left (instead of home team asterisk).
- Deleted a ton of logic from
results and stats.
-
- Remember inner join ignores nulls, so if you’re joining on a nullable column (like
scores.coverer_id to teams.id), you need to do a LEFT join (if scores is on the left of the join, RIGHT if right).
- I use 3 oils for cooking: peanut oil, olive oil, and bacon fat. Lean toward bacon whenever possible. Better flavor, 100% unrefined, etc. The most important other consideration is smoke point: bacon has the lowest, then olive, then peanut has the highest. So for panfrying something on high, must use peanut. For cooking eggs in a skillet on medium, bacon fat is fine. Olive for medium-high pan, or baking.
- SBSC. Continued on the generated cols effort. Results views for coverer and pick points.
- Played with
sqlalchemy-utils‘ observers a bit more.
- Confirmed that they ONLY run when the observed cols change, not on data access.
- Confirmed that it ONLY runs in the ORM layer. If you change the observed cols in psql directly, the observer col does not update. You’d have to go the view +
GENERATED AS col approach for that, but I’m fine living in python for modifications. Shouldn’t be mucking in the db anyway.
- The observer acts as a materialized view. The col is stored. You never have to write it (it also acts as a default!). It’s avail for read.
- You have to
session.commit() to trigger, obviously, because the observer runs in the before_flush phase.
- The only imperfection (but still liveable), with a score example: The
Score.line relationship needs to exist for the Score.coverer col to be autopopulated, since it pulls from the line relationship for cols to calculate from. At at Score creation time, this isn’t the case; the line relation hasn’t been created yet, the Score is only instantiated with line_id. But that’s ok. We have the ID, we can pass the Line object. This ticket is in the business of speeding up reads not writes.
- Made the observer columns manifest as IDs, and FK to the appropriate remote table. And then a normal sqlalchemy
relationship to pull the object back for convenience use in the ORM. Very clean.
-
- All obvious, but a good overview of the softer culture/process hacks at companies: https://steinkamp.us/post/2022/11/10/what-i-learned-at-stripe.html
- Some private work.
- Massage Envy attempted to charge for a monthly billing cycle after the account was closed. I emailed Rosly, and disputed the charge via citi (well, it will file formally once the charge changes from pending to posted).
- She replied and confirmed the cancellation.
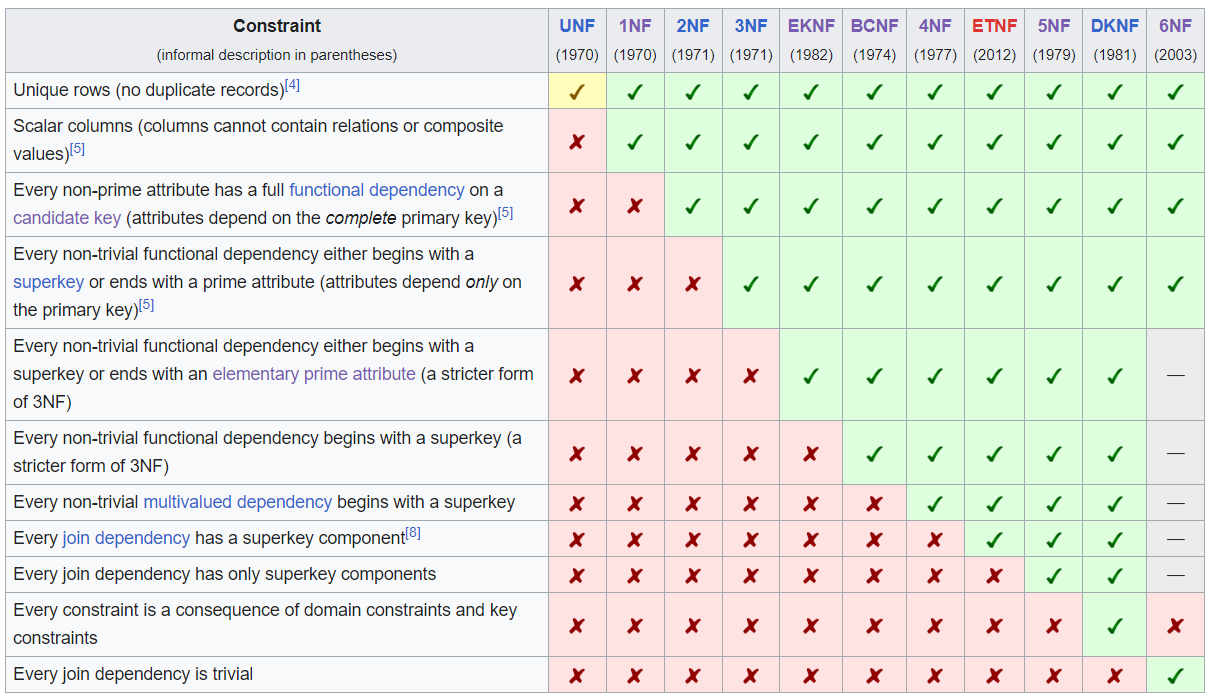
- DB Normalizations.
- Remember they go in strictness order. 2NF is more strict than 1NF. 3NF adds more constraints on top of 2NF.
- I only go over some of the more important distinctions below. There are many more conditions.
- Note also: these only apply to the cols of the table itself (PK, FK, other cols), not sqlalchemy relationships. Those are for the ORM.
- 1NF. Single-valued attributes for each table. No lists. Split those into distinct rows.
- 2NF. “Reduce to atomic tables” – no partial dependencies between cols. Those should be moved to separate tables. Example: season and week, separate tables, if there was just one weeks table with the season info then there would be partial dependencies between the season, season_start, season_end cols in the weeks table.
- 3NF. Same as 2NF but for transitive dependencies between cols. Restated: the relation between the atomic tables is only an FK to the PK, not multiple items or a transitive item.
- ^ That’s where most RDBs can stop normalization and be free from update/insert/delete anomalies. They may still have some redundancy.
- 4NF. Multivalue dependencies. If you a table that has 3 cols A/B/C, split into 2 tables with 2 cols each, A/B and A/C.
- 5NF. Joins are along superkeys (unique value-combos in a row). PK satisfies this.
- 6NF. Every table has at most 1 join dependency. Most common in practice where every table just has a PK and one other col with a value.
- SBSC is 5NF.
- Helpful overview: (ref https://en.wikipedia.org/wiki/Database_normalization)
- SBSC. Started on the results views, for
coverer and points.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/174
- Remember that queries operate on the class of the models, and return instances of those models. Relationships provide their convenience in the latter – for accessing data on objects rather than querying for those objects. You can do a few things with class relationships in the query layer, but mostly for EXISTS (has/any) and comparators (equality). You can’t fetch a value along a relationship and use it in a query, for example, because the relationship requires an object, not a class. So you’d have to subquery to get the object, or something along those lines.
- Sqlalchemy has the
case func for if statements in sql. Maps to when.
- Did a ton of research on options for views in sqla. The native sqla recipe (https://github.com/sqlalchemy/sqlalchemy/wiki/Views),
sqlalchemy-views, and sqlalchemy-utils. I went with the latter. It has a ton of useful tools.
- You can achieve the
Computed behavior of the coverer/points cols by using aggregated or observers. Both support nested relationships to denormalize and bring in data from other tables (like coverer needs Score and Line).
- Aggregates are much better when the one-to-many relationship have thousands of objects on the many side. It does a query for all of them and runs a func on it to product a scalar (an aggregate of your definition).
- Observers are much better for one-to-one or one-to-few, since it just iterates over the related objects, in the transaction. Using observers for this case, since
score.coverer only needs to bring in the one line object (line, favorite, underdog), and pick.points only needs to bring in the one score object (the new coverer col).
- All summarized: need to do a bit of denormalization to calculate the results cols.