-
- Full hedgineer podcast episode released today: https://www.youtube.com/watch?v=3VIGPUsKbAE
- First snow of the season last night!
- Lots of private work.
- MotorGrrl confirmed I can pick the ducati up before the end of the day tomorrow to avoid the March invoice.
- QBR = quarterly business review.
- SBSC. Continued on the new statuses/teams tables, and many corresponding changes that I folded into this ticket.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/175
- Wrote a new
supercontest.models.schemas module. I want the frontend views to match the DB tables as much as possible, keeping app logic thin (and this will only get MORE true with the generated-cols change for results), so the passage of sqlalchemy rows to the frontend becomes more and more direct.
- Since sqla rows are not json-serializable, we have a few options: parse to json-serializable objects (what I was doing before), use python’s builtin
dataclasses module, or an industry-standard third-party. I’ve chosen the latter, marshmallow, since it (as a serialization lib) has plugins to both flask and sqlalchemy.
- Read through the
flask-marshmallow and marshmallow-sqlalchemy docs.
- Included the FKs and relationships in the schemas, and made the relationships nested with the child objects, rather than just PK (marshmallow’s default).
- Note that I had to make the schemas uni-directional for this (all model relationships are bidirectional). This is obviously because it would result in an infinite-length string when serializing. The python ORM doesn’t have to worry about that, all bidirectional relations point to the same underlying/respective object.
- Did a TON of js cleanup.
- All view-specific modules are now pure (functions only), bundled in full by assets but called only in the views they’re needed.
- Merged some of the common behavior (like flashes) into
common.js.
- All the html is correspondingly better; variables are serialized as necessary before being passed by flask, then rendered by jinja into js vars. ONLY the vars necessary are passed, not the overkill of the previous
flask_vars_to_js.html implementation.
- There was a ton of ridiculous
id="<var1>-<var2>-<var3>" behavior in the templates so that js has access to things like userId that jinja populates in the loops. All gone. The js does proper lookups now.
- All of this will clean even further with the React splitout.
- Made it so that
- appears on the regular leaderboard for weeks that were unpicked (rather than 0). A red 0 appears if they submitted 5 picks and hit 0. A regular 0 appears if they did not submitted 1-4 picks and hit 0.
-
- When you update/insert an object with sqlalchemy, write the FK (eg
Score.status_id) not the ORM relationship (eg Score.status). The relationship will autoupdate to the proper object in the other table, based on the FK.
- Bit of private work.
- A big slowdown: running db queries and/or commits in FOR loops. Run them once outside the for loop for a single trip to the data, then store in hashed structures for the python in-memory layer (dictionaries etc). This affected the tables ticket because it helps design queries/commits to return data for iteration/lookup (rather than single functions mapping one datapoint to one datapoint.
- Productivity. Deleted “scratch tasks” note from gkeep. I just scratch on the tickets with intermediary tasks. No need to have a full note all the time, empty almost always. Just create as necessary for non-ticket tasks, or use the appropriate medium for the other tasks. Now my to-do scope is purely gtasks and gcal.
- Don’t use windex on acrylic. The chemical compounds will break it down over time. Bought an acrylic-specific cleaner (and repellent) for the outside of the aquarium.
- Emailed MotorGrrl to see if I can pick up my Ducati on Mar 1 first incurring the next billing cycle.
-
- Lots of cleanup in SBSC. Will post details soon.
- Getting a lot of spam comments on the blog lately (just going to the review queue, not public).
- All prep: software planning, mealprep bacon, oat milk, hibiscus tea, seed powders, new white bulbs in salt lamps, power cable organization, garden care, deepcleaned coffee machine, aquarium maintenance, set up second ember, roomba, cleaned.
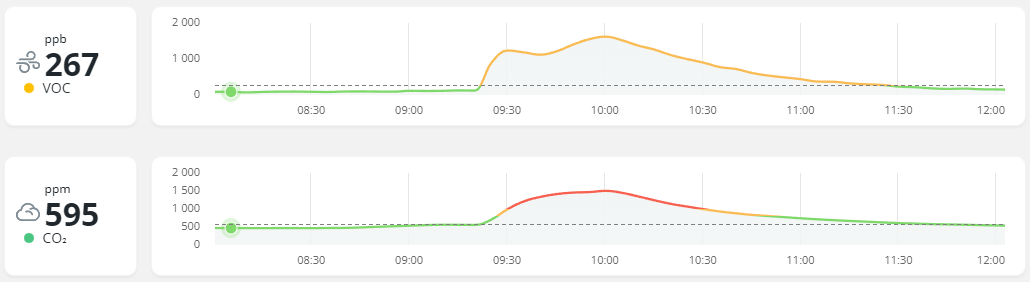
- Interesting. Cooking bacon (oven) spiked my CO2 and VOC levels significantly. Opening the window cleared it within an hour. Temp/humidity/radon/pressure not affected by the cooking.
-
- Some agile planning for the next few tickets.
- Remember that alembic is a migration tool. It’s meant only for database revisions. Changes to the schema.
- I somewhat abuse this for data changes as well. But I only really want this as a record of larger data changes: backfills, important deletions/additions, etc.
- If starting over, I would probably just keep a separate directory for
migrations/scripts alongside migrations/versions. Just like stored procedures.
- I’ll try to start doing that now. It could be sql that I pass to a DO command. Or a python script that uses sqlalchemy (probably easier, since I have access to the app’s helper queries/commits, and more consistent with the migrations).
- Yup, I ended up doing this. Added notes to
ADMIN.md and created the migrations/data_changes folder with an example python script.
- Subscribed to PR notifications in the
graphql-sqlalchemy repo to check specifically when sa2 support is merged: https://github.com/graphql-python/graphene-sqlalchemy/pull/368. I don’t think you can subscribe to single PRs only.
- Bought another ember mug – my current one is 2 years old and is very finicky when starting/stopping/charging. The new one is white/14oz vs the old black/10oz.
- The 3 rise garden nutrients were Sprout, Thrive, and Blossom. You’d add sprout at the beginning, blossom and the end, and thrive throughout all stages. Thrive is a micronutrient blend. Sprout and blossom are macronutrient blends. In the new dry nutrient blends, they combined thrive into both sprout and blossom! So you only add sprout at the beginning (optimized for stems/leaves) and blossom at the end (optimized for fruits/flowers). And you only need to order two thirds as much, so 66% the costs. And they balanced the dry nutrients better for overall health as well as ph, so plants will grow slightly faster/fuller. All around win.
- SBSC. New
teams and statuses tables.
- https://gitlab.com/bmahlstedt/supercontest/-/issues/175
- Fixed all the sequences, their data types, and start values in postgres.
- Added col defaults for all PK ID cols for my 8 tables in pg, set obviously to nextval of the corresponding sequences. 3 of the tables were missing this! Then I can remove it from models, where the sequences were explicitly defined in the ORM layer (saving my butt for those 3). Better to push this to the data layer.
- Sqlalchemy will create the
<table_name>_id_seq and column_default automatically for ID PK INT cols.
- Also note – this is all because I didn’t really know what I was doing when creating the tables originally.
- Some detail (a very good general reference for postgres sequence management) as well as explicit commands on this comment: https://gitlab.com/bmahlstedt/supercontest/-/issues/175#note_1292435219
- Read through a bit of the alembic documentation. Remember to do
alembic.op for the database interactions. You can use sqlalchemy for stuff like datatypes eg sa.Column('id', sa.Integer()). Try not to use db from the supercontest – that’s the flask scoped session manager.
- Another bit of canon: No dependencies on your app within the migrations. It should only depend on the database. This means some convenience queries/commits/utils from your app are unavailable. You don’t have to follow this perfectly. You can use sqlalchemy to bind to the same alembic key and send ORM queries. Or you can use
op.execute to run a select and use those results, if you want to stay 100% in the SQL layer.
- Went through and rewrote the season rollover migration to be a lot cleaner.
- Made the
admin.add_view() for all AdminModelView models dynamic. It inspects the non-FK cols in a table and makes those cols searchable in the admin panel. I was manually maintaining those (breaking often), and copy-pasta of the longer add_view calls. Much cleaner now.
-
- Scary – an intentionally-malicious chrome extension to demonstrate risks: https://mattfrisbie.substack.com/p/spy-chrome-extension
- Lots of private work.
- Hedgineer: https://www.hedgineer.io/
- Followed the twitter (https://twitter.com/hedgineering) and subscribed to yt (https://www.youtube.com/channel/UCbulCxi0-MPPw5mHLLlN0Pg). Already following IG. Joined the slack too.
- All the clips are up: https://www.youtube.com/@hedgineer/videos. Longform full interview soon I think.
- Followup note from yesterday – I can now (and did) remove the google account from my macbook. It was just adding gcontacts, but now that ContactsSync is keeping icloud/gcontacts in sync on my iphone, the macbook just shows icloud (which is everything).
- Web icloud and macbook contacts only show 596, but iphone shows 856 (correct, matching gcontacts). Not sure why.
- Nope – after removing, that delta did result in some missing contacts. Everything fine on phone and google, but icloud/macbook missing some. Added google account back to macbook to be sure.
- Never really used
git stash heavily (weird, I know, it’s a helpful convenience) but played around with it today.
push = running git stash with no arguments (similar to create, but not exactly)pop = apply (but pop removes it from the stash list, apply keeps it there)
-
- Amazon closed its acq of onemedical for $3.9B.
- Lots of private work.
- Finished the sqlalchemy2 upgrade from yesterday (notes on that post).
- https://updraftplus.com/faqs/privacy-policy-use-google-drive-app/
- Switched to the gitlab board view (from milestone) so that I can drag/drop tickets to rank them (order them for next tasks).
- Read up a little bit about loan seasoning. Lending vs trading. Diff regulations.
- WR Chess Masters is very even so far after 7 of 9 rounds. Of the 10-player field, 6 are on 3. 2 are on 4. 2 are on 4.5.
- Moved the bmahlstedt.com domain from godaddy to route53. Unlocked, authed, transfered, approved, relocked, disabled dnssec, added A records to digital ocean droplet IP, confirmed e2e. Fully off godaddy now, all domains registered and DNSed on AWS.
- Calendar / to-do / notes / lists.
- Overall this was an exercise in separating my lists into timed events, timed tasks, and untimed tasks.
- Added a bunch to my gcal so weekly planning is autonomous.
- Also integrated calendars for niners games, ufc events, and warriors games. There’s always the risk of these losing their maintainers as well. Couldn’t find one for chess, so just created one for my own use.
- Started using gtasks. Tasks are tasks. They show up individually to be completed. They allow descriptions. I don’t use reminders. Keep all in one place.
- Took this opportunity to clean up gkeep a little bit as well. Synced the colors with gcal. Moved task lists in gkeep notes (list longterm, cka/cks, etc) to tasks in tasks (separate task lists). Then I can add dates to any individual task and it will automatically show up in gcal!
- Also means that I switch from month view to week view (as default) on desktop and day view on mobile.
- There’s also the “schedule” view which just shows the lists by day (instead of cal by time), which looks a lot like my old management of gkeep.
- So events go in gcal (must have a date or datetime). Tasks go in gtasks (can have no date or datetime). And scratch goes in gkeep.
- Remember gcal has the right side panel (on desktop) to show gkeep and gtasks. Gmail has the right side panel (on desktop) for gcal, gkeep, and gtasks. Gkeep and gtasks don’t have side panels. On mobile, none of these have side panels. So on desktop, just use gmail as the entry point! On mobile, use gcal and gmail and gkeep and gtasks as separate apps.
- This also resulted in some cleanup of types. I did events for most things, even if tasks. Now I switched those to tasks.
- Also I like having gym on gcal – there is the possible to shift the whole schedule (literally all future events) back a day if I miss/skip/etc, but I can also just move one event and keep the remaining schedule. Encourages me to compress and get back to the regular routine instead of pushing everything.
- Disabled Google account from syncing contacts directly on the iPhone. Don’t need it now that Contacts Sync is manifesting them as icloud contacts.
- Contacts.
- Pruned/merged/edited/added/cleaned.
- Added a bunch of birthdays during the cleanup.
- Cleaned and exported icloud contacts too. Then deleted.
- So google contacts is my (only) source of truth. 856 there. 0 icloud.
- Note that there is no google contacts app for iphone (apple’s intention). So you have to add contacts to apple’s icloud and then sync as desired.
- To avoid this, I’m gonna use an app. Looks like the canonical one is Contacts Sync.
- Free tier only does 40 contacts. Paid $8 for lifetime access. Will now autosync all my contacts in both directions.
- Note icloud autoinjects YOUR vcard from the icloud account into icloud contacts (even if you delete it).
- Configured to autosync every 5 min. Or whenever I enter a new location.
- Now I never have to deal with this again.
-
- Filled both rise gardens. 68 plants growing. Added a little bit of sprout/thrive, ph, water. Removed the nurseries from the app so the “plant more seeds” tasks are disabled (and bc I’m skipping the nurseries).
- Got some work done on the private company.
- SQLAlchemy 2.0. General research. SBSC upgrade.
- All details on the ticket: https://gitlab.com/bmahlstedt/supercontest/-/issues/199.
- Don’t want to copy here, but there is a LOT of content on that ticket. I’ll link to the main comments below.
- Deepdived
flask-sqlalchemy: https://gitlab.com/bmahlstedt/supercontest/-/issues/199#note_1288605006
- Review of the primary 2.0 changelog: https://gitlab.com/bmahlstedt/supercontest/-/issues/199#note_1288654017
- Excellent general reference for sqlalchemy usage: https://gitlab.com/bmahlstedt/supercontest/-/issues/199#note_1288673543